1. High Availability - Hướng dẫn triển khai Rabbit Cluster trên CentOS 7
High Availability - Hướng dẫn triển khai Rabbit Cluster trên CentOS 7
Nơi chứa các tài liệu tham khảo của dịch vụ Cloud365.
Cluster là kiến trúc nâng cao khả năng sẵn sàng cho các hệ thống dịch vụ. Hệ thống Cluster cho phép nhiều máy chủ chạy kết hợp, đồng bộ với nhau. Hệ thống Cluster nâng cao khả năng chịu lỗi của hệ thống, tăng cấp độ tin cậy, tăng tính đảm bảo, nâng cao khả năng mở rộng cho hệ thống. Trong trường hợp có lỗi xảy ra, các dịch vụ bên trong Cluster sẽ tự động loại trừ lỗi, cố gắng khôi phục, duy trì tính ổn định, tính sẵn sàng của dịch vụ
Cluster thường được tìm thấy ở các hệ thống thanh toán trực tuyến, ngân hàng, các cơ sở dữ liệu, hệ thống lưu trữ ..
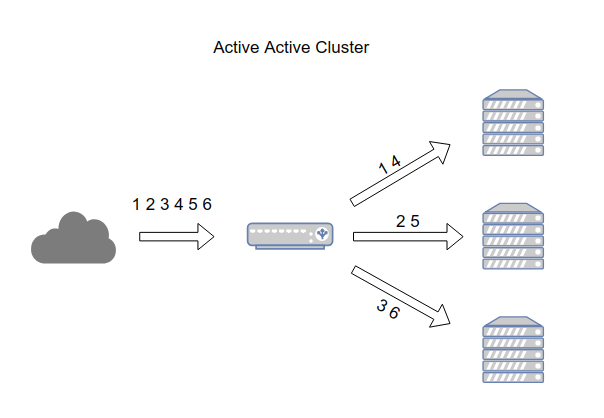
Load Balancing): Các node bên trong cluster hoạt động song song, chia sẻ các tác vụ để năng cao hiệu năng.High availability): Các tài nguyên bên trong cluster luôn sẵn sàng xử lý yêu cầu, ngay cả khi có vấn đề xảy ra với các thành phần bên trong (hardware, software).scalability): Khi tài nguyên có thể sử dụng của hệ thống tới giới hạn, ta có thể dễ dàng bổ sung thêm tài nguyên vào cluster bằng các bổ sung thêm các node.reliability): Hệ thống Cluster giảm thiểu tần số lỗi có thể xảy ra, giảm thiểu các vấn đề dẫn tới ngừng hoạt động của hệ thống.Cluster: Nhóm các server dành riêng để giải quyết 1 vấn đề, có khả năng kết nối, sản sẻ các tác vụ.Node: Server thuộc ClusterFailover: Khi 1 hoặc nhiều node trong Cluster xảy ra vấn đề, các tài nguyên (resource) tự động được chuyển tới các node sẵn sàng phục vụFailback: Khi node lỗi phục hồi, sẵn sàng phục vụ, Cluster tự động trả lại tài nguyên cho nodeFault-tolerant cluster: Để cập đến khả năng chịu lỗi của hệ thống trên các thành phần, cho phép dịch vụ hoạt động ngay cả khi một vài thành phần gặp sự cốHeartbeat: Tín hiệu xuất phát từ các node trong cụm với mục đích xác minh chùng còn sống và đang hoạt động. Nếu heartbeat tại 1 node ngừng hoạt động, cluster sẽ đánh dấu thành phần đó gặp sự cố và chuyển tài nguyên tại node lỗi sang node đang sẵn sàng phục vụInterconnect: Kết nối giữa các node. Thường là các thông tin về trạng thái, heartbeat, dữ liệu chia sẻ.Primary server, secondary server: Trong cluster dạng Active/Passise, node đang đáp ứng giải quyết yêu cầu gọi là Primary server. Node đang chờ hay dự phòng cho node Primary server được gọi là secondary serverQuorum: Trong Cluster chứa nhiều tài nguyên, nên dễ xảy ra sự phân mảnh (split-brain - Tức cluster lớn bị tách ra thành nhiều cluster nhỏ). Điều này sẽ dẫn đến sự mất đồng bộ giữa các tài nguyên, ảnh hướng tới sự toàn vẹn của hệ thống. Quorum được thiết kế để ngăn chặn hiện tượng phân mảnh.Resource: Tài nguyên của cụm, cũng có thể hiểu là tài nguyên mà dịch vụ cung cấpSTONITH/ Fencing: STONITH là viết tắt của cụm từ Shoot Other Node In The Head đây là một kỹ thuật dành cho fencing. Fencing là kỹ thuật cô lập tài nguyên tại từng node trong Cluster. Mục tiêu STONITH là tắt hoặc khởi động lại node trong trường hợp Node trong trường hợp dịch vụ không thể khôi phục.Active Active cluster được tạo ra từ ít nhất 2 node, cả 2 node chạy đồng thời xử lý cùng 1 loại dịch vụ. Mục đích chính của Active Active Cluster là tối ưu hóa cho hoạt động cân bằng tải (Load balancing). Hoạt động cân bằng tải (Load balancing) sẽ phân phối các tác vụ hệ thống tới tất cả các node bên trong cluster, tránh tình trạng các node xử lý tác vụ không cân bằng dẫn tới tình trạng quả tải. Bên cạnh đó, Active Active Cluster nâng cao thông lượng (thoughput) và thời gian phản hổi
Khuyển cáo cho chế độ Active Active Cluster là các node trong cụm cần được cấu hình giống nhau tránh tình trạng phân mảnh cụm.
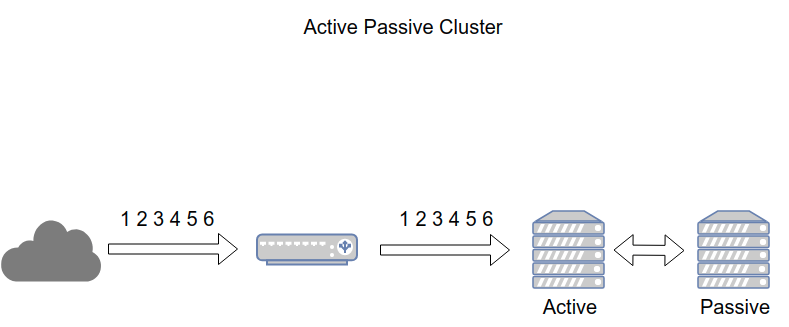
Giống cấu hình Active - Active, Active Passive Cluster cần ít nhất 2 node, tuy nhiên không phải tất cả các node đều sẵn sàng xử lý yêu cầu. VD: Nếu có 2 node thì 1 node sẽ chạy ở chế độ Active, node còn lại sẽ chạy ở chế độ passive hoặc standby.
Passive Node sẽ hoạt động như 1 bản backup của Active Node. Trong trường hợp Active Node xảy ra vấn đề, Passive Node sẽ chuyển trạng thái thành active, tiếp quản xử lý các yêu cầu
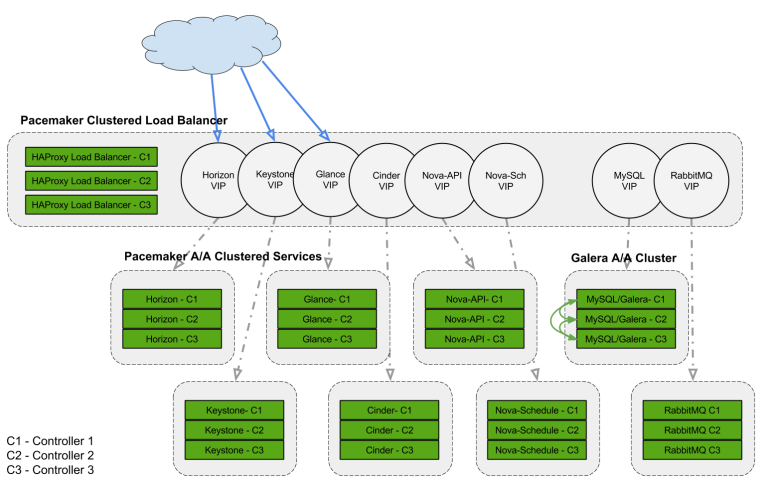
Mô hình Openstack Cluster
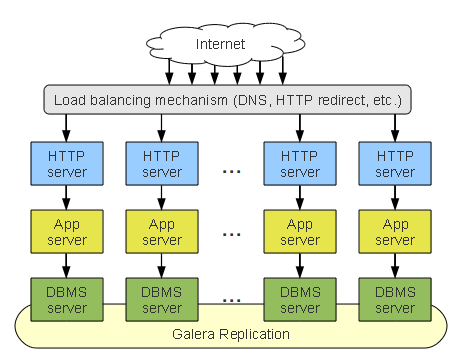
Mô hình Galera Cluster
Mô hình Ceph Cluster
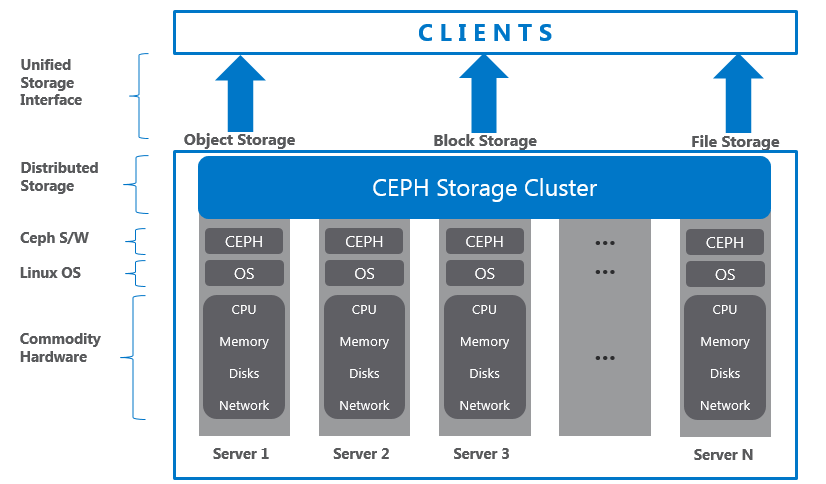
https://lacoski.github.io/ceph-overview/
https://github.com/hocchudong/ghichep-pacemaker-corosync
http://people.redhat.com/tcameron/Summit2017/HAClustering/HA_Clustering_with_RHEL7.pdf
http://clusterlabs.org/pacemaker/doc/en-US/Pacemaker/1.1/pdf/Clusters_from_Scratch/Pacemaker-1.1-Clusters_from_Scratch-en-US.pdf
Thực hiện bởi cloud365.vn
Chuồi các bài viết về High Availability cho các thành phần trong Web Server
High Availability - Hướng dẫn triển khai Rabbit Cluster trên CentOS 7
Hướng dẫn triển khai Haproxy Pacemaker cho Cluster Galera 3 node trên CentOS 7
Tổng quan về Resource trong Pacemaker
Tổng quan về Quorum, STONITH/Fencing
Tổng quan về Pacemaker Corosync
Tổng quan về Cluster