1. ELK part 6 - Tìm hiểu về logstash.
Tìm hiểu về logstash.
Nơi chứa các tài liệu tham khảo của dịch vụ Cloud365.
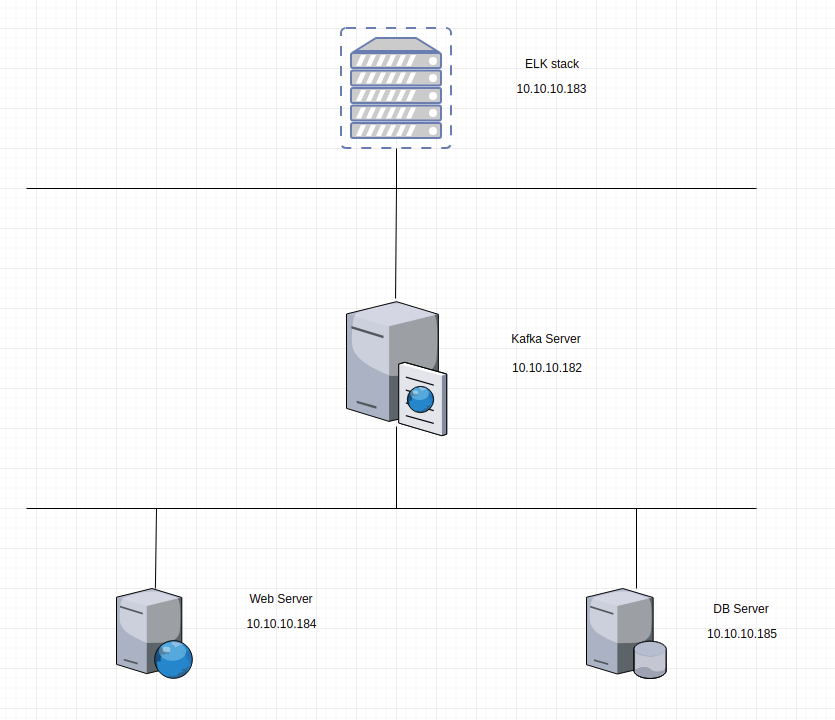
Ở bài trước mình đã giới thiệu cách đẻ join cluster Elasticsearch để tối ưu cho việc lưu trữ và tìm kiếm thông tin của hệ thống ELK. Hôm nay mình giới thiệu cách sử dụng kafka làm cache cho hệ thống ELK, đây là giải pháp tối ưu khi log từ client đẩy về ELK nếu như số lượng log quá nhiều cùng một lúc đẩy vào hệ thống ELK thì khả năng treo node sẽ có khả năng xả ra rất cao do đó hôm nay mình viết bài này để giới thiệu đến mọi người một giải pháp có thể giảm thiểu việc node ELK bị treo.
1 máy CentOS 7 làm ELK (aio) server : RAM 6GB, 100GB HDD.
1 máy CentOS 7 làm kafka : RAM 4GB, 100GB HDD
Các máy client có OS là windows, ubuntu hoặc CentOS.

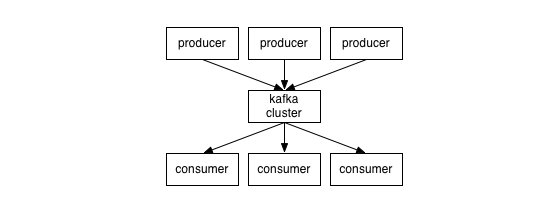
Kafka là hệ thống message pub/sub phân tán mà có khả năng scale.
Message của kafka được lưu trên đĩa cứng, đồng thời được replicate trong cluster giúp phòng tránh mất dữ liệu.
Kafka có thể hiểu là một hệ thống logging, nhằm lưu lại các trạng thái của hệ thống, nhằm phòng tránh mất thông tin.
Các khái niệm cơ bản :
Kafka lưu, phân loại message theo topics.
Kafka sử dụng producers để publish message vào các topics ở trên.
Kafka sử dụng consumers để subscribe vào topics, sau đó xử lý các message lấy được theo một logic nào đó.
Kafka thường được chạy dưới dạng cluster, khi đó mỗi server trong đó sẽ được gọi là broker.
Topic có thể hiểu là một ngôn ngữ chung giữa producer (người nói) và consumer (người nghe, sử dụng). Với mỗi topic, kafka sẽ duy trì thông qua partitioned log như dưới đây:
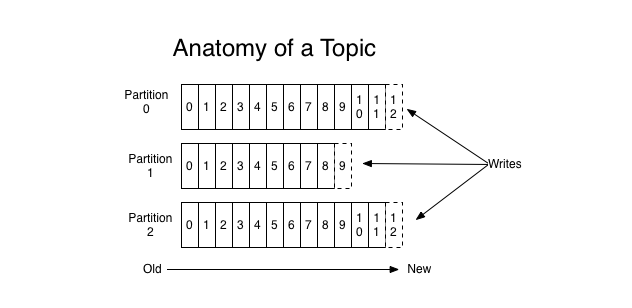
Mỗi partition là một chuỗi log, có thứ tự và không thể thay đổi (immutable).
Mỗi message trong partition sẽ có id tăng dần , gọi là offset.
Kafka cluster sẽ lưu lại mọi message đã được published, cho dù message đó đã được/chưa được sử dụng (consume). Thời gian lưu message có thể tuỳ chỉnh được thông qua log retention.
Consumer sẽ điều khiển những gì mình muốn đọc thông qua offset của message, hay thậm chí là thứ tự đọc. Consumer có thể reset lại vị trí của offset để re-process lại một vài message nào đó.
Như đã nói ở trên, producer nhằm mục đích chính là ném message vào topic. Cụ thể hơn là producer có nhiệm vụ là chọn message nào, để ném vào partition nào trong topic. Nhiệm vụ này rất quan trọng, giúp cho kafka có khả năng “scale” tốt.
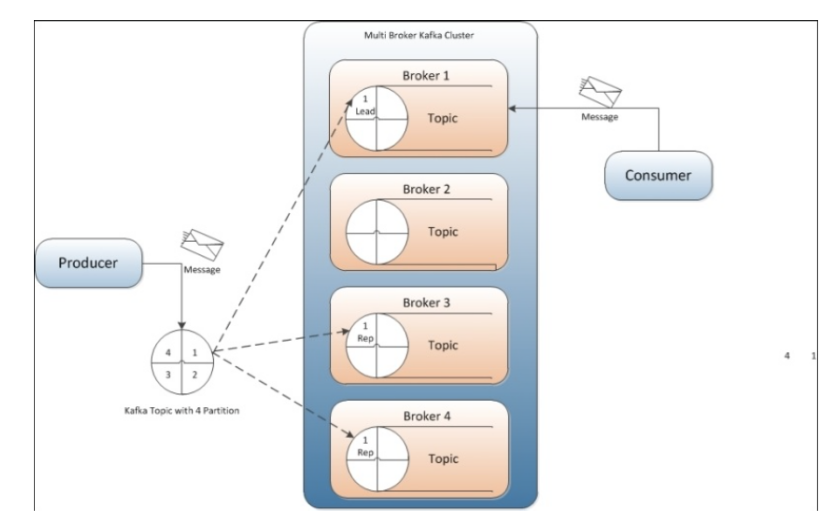
Thông thường thì một hệ thống messaging sẽ có 2 loại :
Queue: Một message sẽ được xử lý bời một consumer.
Pub/Sub: Một message sẽ được xử lý bởi một vài consumer thích hợp, tuỳ theo topic.
Ở kafka chúng ta có một khái niệm gọi là consumer group giúp chúng ta có thể làm được đồng thời cả 2 loại trên, rất thú vị. Việc subscribe một topic sẽ được thực hiện bởi consumer group. Mỗi một message sẽ được gửi cho duy nhất một consumer instance trong một consumer group. Việc này dấn đến :
Nếu nhiều instance consumer có cùng group: chúng ta sẽ có một hệ thống queue.
Nếu mỗi instance là một group, chúng ta sẽ có một hệ thống pub/sub.
Sử dụng như một hệ thống message queue thay thế cho ActiveMQ hay RabbitMQ.
Tracking hành động người dùng : các thông số như page view, search action của user sẽ được publish vào một topic và sẽ được xử lý sau.
Log Aggregration: log sẽ được gửi từ nhiều server về một nơi thống nhất, sau đó có thể được làm sạch và xử lý theo một logic nào đó.
Event-Sourcing: Lưu lại trạng thái của hệ thống để có thể tái hiện trong trường hợp system bị down.
Việc cài đặt ELK thì mình đã giới thiệu với mọi người ở Part 2 mọi người có thể tham khảo cài đặt, dưới đây là cách để tích hợp kafka vào làm cache cho ELK.
Download kafka:
yum install wget -y
wget http://mirror.downloadvn.com/apache/kafka/1.1.0/kafka_2.11-1.1.0.tgz
Giải nén kafka:
tar -zxvf kafka_2.11-1.1.0.tgz
Cài đặt Java:
yum install java-1.8.0-openjdk -y
Cấu hình enviroment:
echo "export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk" >> /etc/environment
echo "export JRE_HOME=/usr/lib/jvm/jre" >> /etc/environment
Mở firewall:
firewall-cmd --add-port=9092/tcp
firewall-cmd --add-port=9092/tcp --permanent
Truy cập vào file cấu hình kafka:
cd kafka_2.11-1.1.0
vi config/server.properties
Mở file cấu hình tìm từ khóa listeners và cấu hình lại :
listeners=PLAINTEXT://ip-kafka:9092
Chạy file run:
yum install -y screen
screen -d -m bin/zookeeper-server-start.sh config/zookeeper.properties
screen -d -m bin/kafka-server-start.sh config/server.properties
Tạo topic mới để nhận log:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic log-system
Kiểm tra trạng thái cluster:
ps aux | grep zookeeper.properties
ps aux | grep server.properties
List các topic hiện có:
bin/kafka-topics.sh --list --zookeeper localhost:2181
Theo dõi các message có trong topic:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic log-system
Tạo file cấu hình logstash:
vi /etc/logstash/conf.d/02-logstash.conf
Thêm vào file cấu hình nội dung như sau:
input {
kafka {
bootstrap_servers => 'ip-kafka:9092'
topics => ["log-system"]
codec => json {}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
sniffing => true
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
}
}
Khởi động lại logstash:
systemctl restart logstash
Mở file cấu hình filebeat:
vi /etc/filebeat/filebeat.yml
Sửa lại cấu hình filebeat như sau:
filebeat:
prospectors:
- paths:
- /var/log/*.log
encoding: utf-8
input_type: log
fields:
level: debug
document_type: type
registry_file: /var/lib/filebeat/registry
output:
kafka:
hosts: ["ip-kafka:9092"]
topic: log-syslog
logging:
to_syslog: false
to_files: true
files:
path: /var/log/filebeat
name: filebeat
rotateeverybytes: 1048576000 # = 1GB
keepfiles: 7
selectors: ["*"]
level: info
Khởi động lại filebeat:
systemctl start filebeat
Thực hiện bởi cloud365.vn
Chuỗi bài giới thiệu về giải pháp ELK
Tìm hiểu về logstash.
Tìm hiểu về filebeat.
Cài đặt ELK sử dụng kafka làm cache
Tài liệu về ELK stack
Tài liệu về ELK stack
Tài liệu về ELK stack